"A gambler, frustrated by persistent horse-racing losses and envious of his friends' winnings, decides to allow a
group of his fellow gamblers to make bets on his behalf. He decides he will wager a fixed sum of money in every
race, but that he will apportion his money among his friends based on how well they are doing. Certainly, if he
knew psychically ahead of time which of his friends would win the most, he would naturally have that friend handle
all his wagers
Introduction
Ensemble methods, combining the results of individual predictions to achieve even better results than the individual parts, are ubiquitous in data science and machine learning. Freund & Schapire’s AdaBoost has become synonymous with ensemble methods. While AdaBoost focuses on boosting, making a strong learner out of weak ones, this article will focus on extending the techniques of AdaBoost to a slightly reformulated problem.
In supervised learning scenarios, it is common to come up with several performant
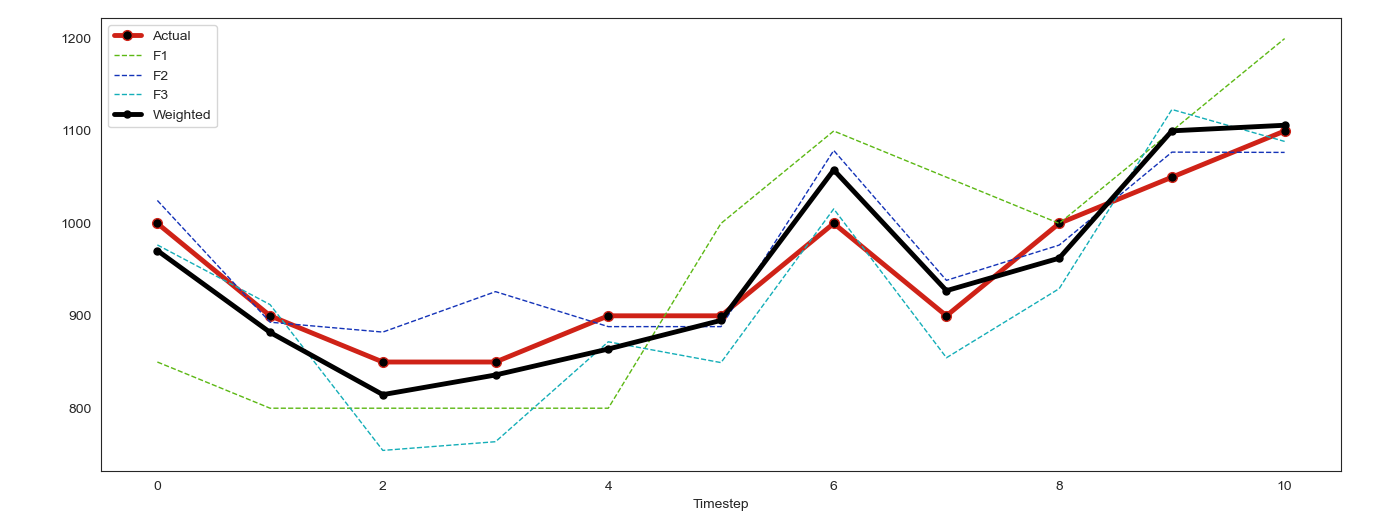
If our predictions are temporally ordered, i.e. forecasts or time series, then as time passes it is likely that we will see the relative performance of a model trend up or down. Several natural questions arise from this behavior.
- How can we design an online algorithm to adjust relative weights of each model as their performance changes over time?
- If we have multiple related time series, can we gain performance from combining each model uniquely for each forecast? Put another way, we might apply the technique to each time series individually, rather than the dataset as a whole. The example in this article will consider the case of forecasting visitors to many different restaurants. Other examples might be forecasting sales of many items across many stores or forecasting individual stocks in a mutual fund.
Thus this article will provide an exploration of several methods used to combine forecasts that will answer these questions. The majority of the focus will be on an approach based on AdaBoost and another using online projected gradient descent. We then apply each technique to forecasting restaurant visitors and assess the performance of each method. Finally, we give some extensions and commentary about these techniques.
Towards an Algorithm Inspired by AdaBoost
The goal of AdaBoost is to take weak hypotheses and combine them into a single, final hypothesis:
Original AdaBoost Algorithm
Initialize weights,
Create "weak" models, m=1,...,M:
Fit model m,
Evaluate the model with the corresponding true values
Evaluate
Update
Output
With AdaBoost in mind, to get weights in a way that fits our problem there are some significant and non-obvious
changes that have to be
made. First, we need to see the difference in the problems we are trying to solve. AdaBoost at every iteration is
creating a new model to add to the ensemble, based on the weights it assigns to each data instance. What we are
interested in are just the weights
Adaptive Weighting Algorithm
AdaWeight
Input:
return
Here we have the pseudocode for AdaWeight. The algorithm starts by taking as input an array of
Initially, the algorithm sets the current weights
Once we have the error
Online Projected Gradient Descent
The Adaptive Weighting algorithm as presented in the previous section has a striking similarity to online gradient descent.
Online Gradient Descent
Initialize
for i = 1,...,t-1:
Get
return
Breaking it down, we first notice how the loop here represents iterating over every timestep, so we can ignore it for now, since later we can just apply the algorithm iteratively to each new set of weights w.
| Online Gradient Descent | AdaWeight |
|---|---|
| Get Incur cost |
|
| nudge = |
|
The first line is equivalent to having the
Similar to our power absolute error function in AdaWeight, we define our loss function for gradient descent
as
Now the question remains of how to project our weights after the nudge to ensure that we stay within our
constraint set
This is exactly the constraint set for a projection onto a probability simplex. Efficient algorithms exist to
compute this projection, the algorithm Project comes from a short paper from UC Merced
Project
Input:
p = max{for j=1,...,D:
return
Using this projection function gives us the closest vector that is inside our constraint set in terms of the L2 norm. This is opposed to the naive approach of normalizing the data to sum to 1 and clipping negative values to 0, which would not give us such a statement of being optimal in terms of the L2 norm.
Putting the pieces together now gives us our final algorithm.
Online Projected Gradient Descent for Weighting
Input:
return
Testing on Synthetic Data
Here we will run AdaWeights and gradient descent on synthetic data to build intuition on how they work and as a sanity check to see if they behave as we expect.
Test 1
We generate forecasts from three different normal distributions. They will all be centered around the same true value, but with different standard deviations. This will represent one clear best forecast, SD10, one middle ground, SD25, and one clear worst, SD100. In this scenario we would expect to see the best forecast have a very high weight, the next best with a smaller weight, and the worst with a weight near zero, given enough iterations.
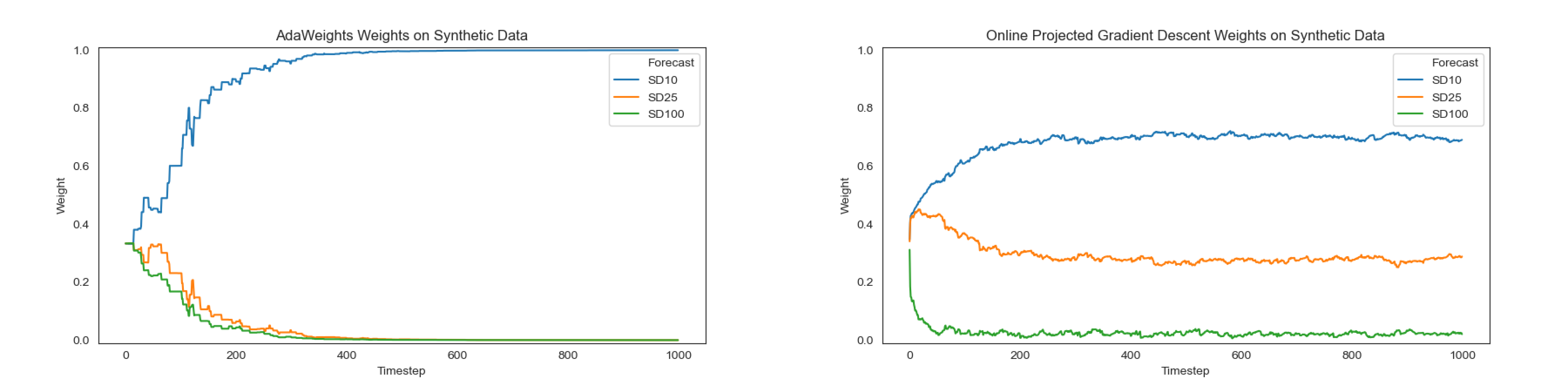
Note that both algorithms were run on the same synthetic data.
Test 2
Here we generate forecasts from three of the same normal distributions. Each is centered around 1000 with a standard deviation of 25. In this case we would likely want each forecast to be weighted similarly to maximize diversity in our ensemble.
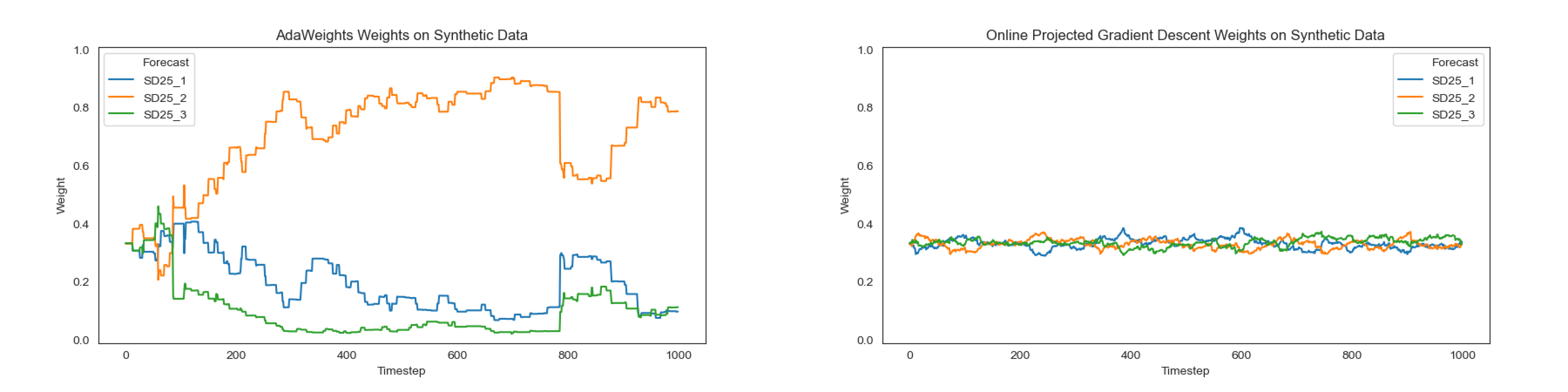
Note that both algorithms were run on the same synthetic data.
Stacking
Now that we have two optimization based algorithms, let's briefly look at a well-known method that leverages
machine learning. Stacking, gaining fame from the top 2 Netflix prize solutions
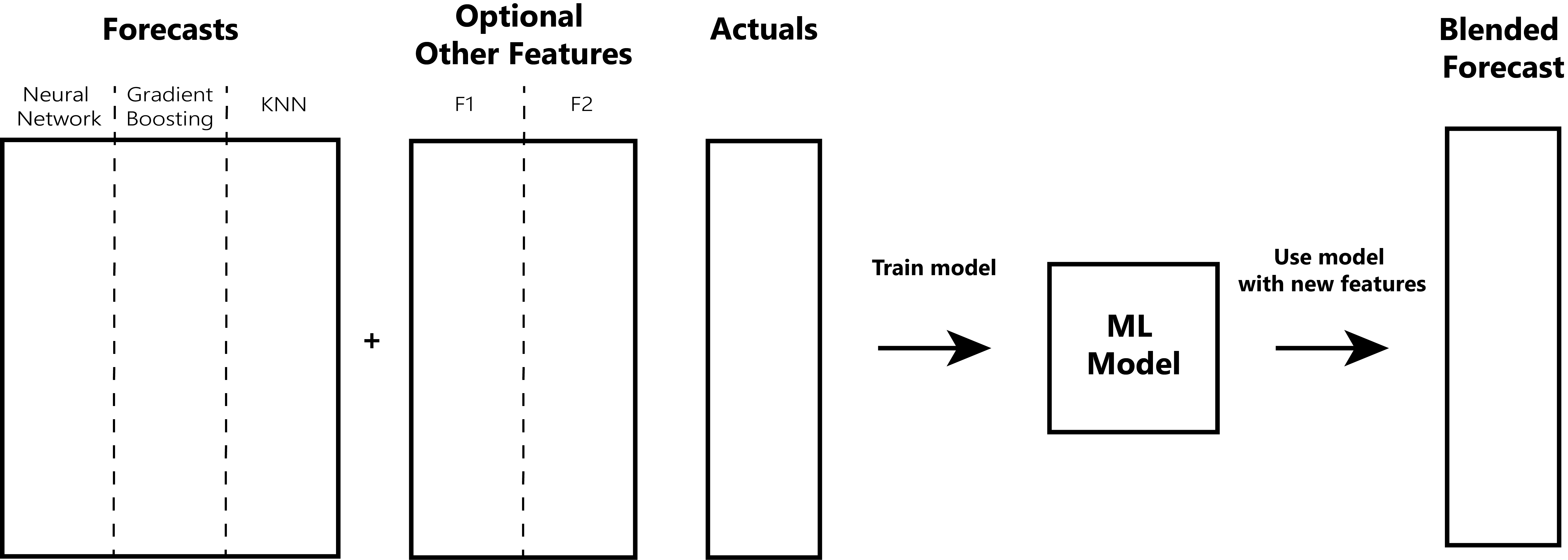
We have some set of forecasts we already generated and an optional dataset of associated features. These extra features can be anything that we think will help the blending model create a better prediction. These features combined with the target actuals are used to train a new model. We then use this trained model to generate a single, blended forecast (of course in practice we would provide it out of training sample data).
Practical Example
Now we turn to testing each algorithm on a real dataset, courtesy of an old Kaggle competition. The goal of the Recruit Restaurant Visitor Forecasting competition was to predict how many future visitors a restaurant/store will receive.
We took models from top performing kernels in order to get a variety of different forecasts to test our algorithms on. The first set of three models are based on the 8th place solution. They each use the features as described in that notebook (see Implementations and Code to Reproduce section for our code). All the models using these features are gradient boosting based. Two use Microsoft’s LightGBM and the other is XGBoost. For undetermined reasons, all three of these models underperformed overall, but we decided to keep them in as a good test of what happens if models start to perform poorly!
The second set of four models come from the notebook Exclude same wk res from Nitin's SurpriseMe2 w NN by Kaggle user Andy Harless. From this notebook we take 4 models that all use a different set of features compared to model set 1. The model families are GradientBoosting from Sklearn, KNN, XGBoost, and a feed forward neural network implemented using Tensorflow 2.
Instead of submitting our results to the competition to get the hidden scores, we opted to only use the provided data in order to be able to break down the problem into a more useful scenario. We generate forecasts using the models trained weekly rather than in one sequence of 39 days. For example, for the first period we stop training with data from before 2017-03-02. Then we generate predictions for the next seven days: 2017-03-04 to 2017-03-10. We repeat this process for the following 5 weeks of data, moving up the end of the training data each time. In this way, we prevent data leakage because a prediction for any day was made with data from at least two days before.
We apply each of the three previously discussed algorithms to the generated forecasts. Our baseline is to naively
weight each model based on how they did overall on test data as it was described in the beginning of this article.
For AdaWeight and gradient descent we create a matrix of weights that we use to apply to the set of forecasts
two
days into the future. So if AdaWeight’s last iteration was for 2017-04-02, then the weights it generated are
applied to the forecasts for 2017-04-04. This can be thought of as lagging the generated weights by two days to
ensure that we are not leaking data by using actuals to generate weights for that same day. In this way we ensure
that we simulate a realistic environment since you would not have the actual value until at least the next day.
The dataset consists of visitor counts to hundreds of stores. We treat each store as a separate time series, so
the algorithm is applied from a "cold start" for each store in the dataset. We also note that we start off each
algorithm with the
For stacking we create a model trained on data from 2017-03-04 to 2017-03-27. The model we chose as the blender was LightGBM and used hyper parameters close to the defaults which are effective for many other problems. We also provide the model with two additional features, the store and the day.
Here is a comparison of how each individual model and each ensemble method performed tested on forecasts from 2017-03-29 to 2017-04-22. We use RMSLE as our metric as is done in the competition.
| RMSLE | |
|---|---|
| GradientBoostingSklearn | 0.54624 |
| KNN | 0.57193 |
| LightGBM_1 | 0.60038 |
| LightGBM_2 | 0.59961 |
| Neural Network | 0.49415 |
| XGBoost_1 | 0.49881 |
| XGBoost_2 | 0.58884 |
| Naive Weighted | 0.48753 |
| AdaWeight | 0.48801 |
| Online Projected Gradient Descent | 0.48826 |
| Stacking w/LightGBM | 0.54625 |
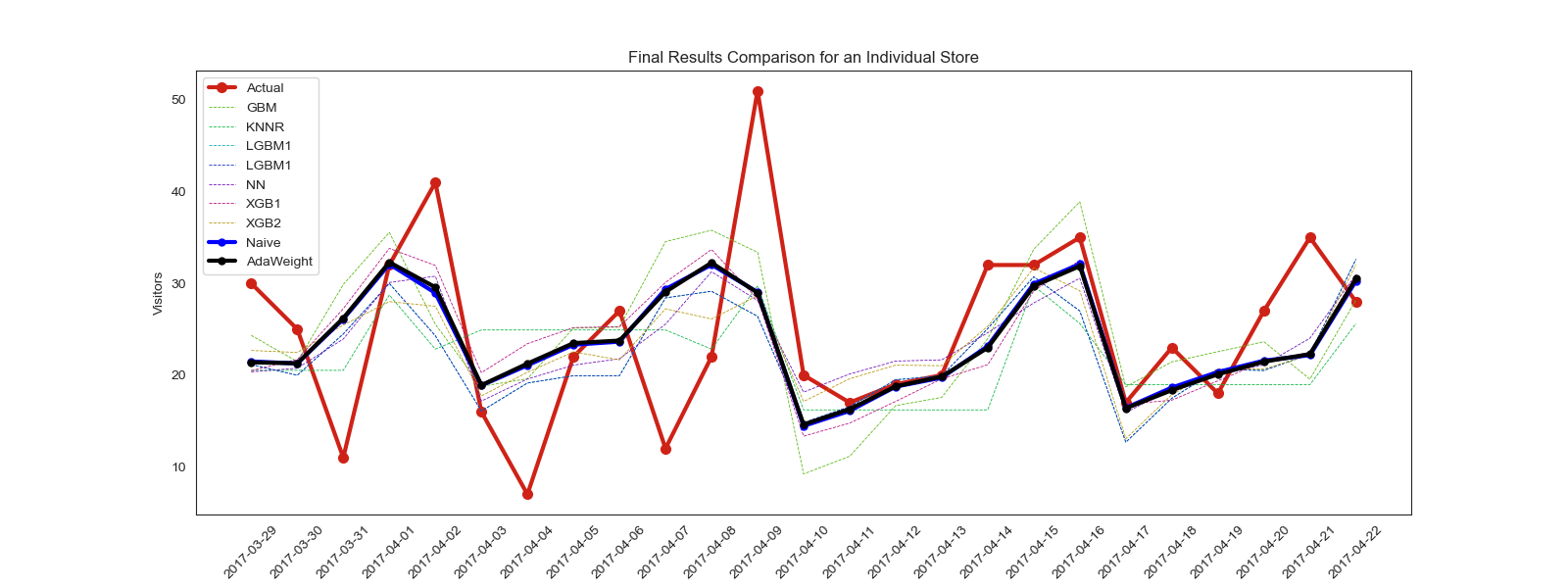
The tabular results show that AdaBoost and Gradient Descent are both essentially identical to the naively weighted solution and beat the best individual model by a fair margin. Stacking lags far behind doing about as well or worse than if each model was weighted evenly. In regards to the plot, it becomes more apparent that a good set of naive weights compared to the algorithm does not make a significant difference, positive or negative, in the overall results.
Extensions
The loss function chosen for the gradient descent algorithm is based on a combination of mean squared error and
absolute error. There are likely other differentiable metrics that could be used for the minimization problem.
Similarly, in regards to AdaWeights, the error function could also be modified to have additional properties. One
clever metric might be to take into consideration the pairwise bias of the forecasts. The intuition behind this is
that just choosing the best single model is not optimal when you have one forecast above and another below the
true value. In this scenario, you could find a weight that gives you exactly the point forecast. With this in
mind, you might be more inclined to weight higher forecasts that are biased in opposite ways. In our current
algorithm, two forecasts that are both biased in the same way (i.e. are nearly identical) are treated the same as
two forecasts that are biased in opposite ways to each other. Perhaps put another way, it might be useful to find
a metric that boosts diversity in your forecasts.
An intuitive optimization of both
An interesting experiment would be to test prior weights and see how long takes for the prior to be irrelevant. Or in other words, how many iterations it takes until the weights starting with and without the prior are equal.
Conclusion
We presented two online algorithms for adjusting the relative weights of models as their performance changes over time. AdaWeights was inspired by the machine learning algorithm AdaBoost and utilized some of the mathematics behind it. The second was an application of online projected gradient descent, a method ubiquitous in continuous optimization. We also presented another common ensemble technique, stacking, to compare its results alongside. While AdaWeights and gradient descent did not have a large improvement over our naive baseline, they are still worthy considerations in problems where ensembling large amounts of models for many time series is required. We showed how each algorithm is able to automatically adjust weights of each forecast to keep up with its relative recent performance. Such a method could be invaluable in a scenario where it is infeasible for a human to monitor the performance of each model over every time series. These algorithms allow for a hands off approach to creating a blend of forecasts. Finally, we provide implementations and code to reproduce the experiments in the Github repository described below.
If you liked this article, consider reading my first article on a method for correcting forecast errors based on it’s previous errors. If you want to be informed of other data science and machine learning news head over to mlfeed.tech or follow MLTwitterFeed on Twitter.
Implementations and Code to Reproduce
Code implementing AdaWeights and gradient descent and code to reproduce the various experiments and models can be
found on Github. It was written and tested using
Python 3.7.4 64-bit on Windows and a list of package
requirements is provided in requirements.txt.
- Algorithm implementations are in
optimization.py. - Using these algorithms and how to recreate the experimental results using them is in the jupyter notebook
AdaWeighting.ipynb. - Code to create the feature engineered datasets and models used to generate the predictions used can be found
in
mk_datasets.py. - Code to generate the predictions can be found in
mk_predictions.py. - Code for creating the various figures used in this article is located in
Figures.ipynb.